AMD Ryzen 9 9950X vs 9950X3D
In-depth performance comparison for Linux server workloads, homelab AI/ML inference, dual-GPU setups, and the best budget motherboard for multi-GPU machine learning — the ASUS ProArt X870E-Creator WiFi
| Cores / Threads | 16 / 32 |
| Microarchitecture | Zen 5 "Granite Ridge" |
| L3 Cache | 64 MB (32 MB per CCD) |
| Max Boost Clock | 5.7 GHz |
| TDP | 170 W |
| Process Node | TSMC 5 nm (N5) |
| Socket | AM5 / DDR5-6000 |
| AVX-512 | Sky Lake (128-bit) fold-to-256 |
| Street Price (May 2026) | ~$498 |
| Cores / Threads | 16 / 32 |
| Microarchitecture | Zen 5 "Granite Ridge" |
| L3 Cache | 144 MB (96 MB on CCD0 + 48 MB on CCD1) |
| Max Boost Clock | 5.7 GHz |
| TDP | 170 W |
| Process Node | TSMC 5 nm + SoIC (3D-stitched) |
| Socket | AM5 / DDR5-6000 |
| AVX-512 | Sky Lake (128-bit) fold-to-256 |
| Street Price (May 2026) | ~$574 |
Hardware Architecture — What's Different Under the Hood?
Key difference: The 9950X3D stacks a 64 MB SRAM layer via SoIC hybrid bonding on CCD0 — giving that die 96 MB L3 total. Combined with CCD1's 48 MB, that's 144 MB total L3 cache versus the 9950X's 64 MB. AMD's upcoming 9950X3D2 (dual V-Cache CCDs) pushes this to 192 MB at a higher price.
L3 Cache Capacity Comparison
Ryzen 9 9950X (AM5 Package)
The 3D V-Cache Advantage
How it worksCritical Differentiator
The 9950X and 9950X3D share the same Zen 5 CCD silicon — identical IPC, clock speeds (up to 5.7 GHz), and core count. The solo difference is on CCD0: for X3D models AMD bonds a 64 MB SRAM layer directly on top of the L3 cache using TSMC's system-on-interconnect-chip (SoIC) hybrid-bumping technique at a ~5µm pitch, reducing each cache bit's access latency to roughly 8 ns versus ~14 ns in conventional stack options.
This expanded L3 pool is critical for AI and ML workloads — more model weights, larger KV caches, and embedding tables stay in fast on-die memory instead of traversing the Infinity Fabric to DDR5 (~24 GB/s per channel). For homelab LLM inference, the 3D V-Cache reduces prompt-processing latency by keeping attention matrices and weight tiles in L3, where access is ~4x lower latency than main memory.
Benchmarks at a Glance — Linux 6.13 / Ubuntu 24.04
| Workload Category | 9950X | 9950X3D | Winner |
|---|---|---|---|
| Geometric mean — all Linux benchmarks (400+ tests) | Baseline | Slightly faster overall | ~slight edge 9950X3D |
| Llama.cpp CPU BLAS (prompt processing) | Strong baseline | +5% to +12% tokens/sec | 9950X3D |
| Llama.cpp — Text Generation (token/sec) | ~9 tok/s (8B Q8_0) | ~9.2 tok/s (8B Q8_0) | Tie — memory-bound |
| Whisper.cpp speech-to-text | Strong baseline | Faster inference, same power | 9950X3D |
| OpenVINO + TensorFlow CPU AI | Strong baseline | +10% to +20% improvement | 9950X3D |
| Nginx HTTPS (1,000 concurrent) | Strong baseline | +5% to +8% throughput | 9950X3D |
| ClickHouse (cold cache, 100M rows) | Strong baseline | +7% to +12% query speed | 9950X3D |
| PostgreSQL (scaling factor 100, 500 clients) | Strong baseline | +6% to +10% avg throughput | 9950X3D |
| Embree 4.4 Pathtracer | ~34 FPS | ~40 FPS (+18%) | 9950X3D |
| OpenFOAM CFD — Incompact3D / SPECFEM3D | Strong baseline | +15% to +25% simulation speed | 9950X3D |
| GROMACS molecular dynamics | Strong baseline | +12% to +20% ns/day | 9950X3D |
| C/C++ code compilation (GCC-14, make -j) | Baseline ~1x | +5% to +10% | 9950X3D |
| TDP — under full AVX-512 load | ~170 W (planned) / ~300+ W real | Similar to 9950X, lower peak | Tie (similar) |
| Price (street, May 2026) | ~$498 | ~$574 | 9950X (value) |
Server Workloads — Deep Dive
Node.js Application PerformanceBest: 9950X3D
Phoronix SOHO-server testing shows roughly 5% performance uplift on average for the 9950X3D. Node's event loop benefits from reduced L3 cache misses during heavy JSON serialisation, async I/O callbacks, and large closure-object retention (e.g., Express/Koa middleware chains holding dozens of request-scoped objects).
Practical impact: An Express.js API serving ~12,000 req/s per core on the 9950X scales to ~13,000 req/s on the 9950X3D — consistent with ~8% tail-latency improvement in high-throughput containerised node microservices.
MariaDB / MySQL Database PerformanceBest: 9950X3D
The 9950X3D out-performs the base 9950X in database workloads because the expanded L3 pool holds more of the active InnoDB buffer pool and query result set cache. Phoronix testing showed ClickHouse cold-cache hits improving by roughly 7–12%.
Why it matters for MariaDB: InnoDB data pages, redo-log structures, and temporary-sort tables all benefit from 144 MB of on-die storage keeping hot data away from memory-controller contention.
Llama.cpp Server PerformanceBest: 9950X3D
llama.cpp benchmarks (CPU BLAS, Q8_0 quantised models) show the 9950X3D delivering +5% to +12% more tokens-per-second in prompt-processing — the stage where model weights stream through L3 cache. Real-world results from the homelab community show a 9950X with 96 GB DDR5-6400 running Qwen3-30B-A3B (MoE) at ~17 tok/s CPU-only.
Text generation is memory-bandwidth bound: For token-by-token generation, both CPUs perform similarly (~9 tok/s on 8B Q8_0 models) because the bottleneck is DDR5 bandwidth, not cache. The 3D V-Cache advantage is real for prompt processing and context ingestion but minimal for streaming output.
Docker Workload PerformanceBest: 9950X3D
Docker/OCI containerised workloads benefit indirectly from the expanded L3 cache when containers are running densely packed — node microservices, Java apps (Spring Boot), or Python data-science services holding large datasets in RAM. The 64 MB extra SRAM on CCD0 holds more compressed layers for frequently-spawned ETL jobs.
Code compilation inside build-containers (Docker + make -j, multi-stage builds) showed ~5–10% improvement. In dense K8s node scenarios the 9950X3D provides better tail-latency because inter-node traffic handling in CNI plugins benefits from extra L3.
Homelab AI & Machine Learning — Real-World Performance

Modern homelab AI workstation — triple RTX Pro 4000 Blackwell 24GB GPU, AMD Ryzen 9, ready for 24/7 inference workloads
Prompt Processing vs. Text GenerationCritical for LLM Serving
In LLM inference, there are two distinct phases: prompt processing (prefill) and text generation (decode). The prefill phase processes the entire input prompt in parallel — it is compute-bound and benefits significantly from 3D V-Cache because weight tiles and attention matrices stay in L3. The decode phase generates one token at a time autoregressively — it is memory-bandwidth-bound and sees minimal benefit from additional cache.
OpenBenchmarking data (May 2026) comparing 9950X3D, 9950X3D2, and 9950X on identical hardware shows the ranking 9950X3D2 > 9950X3D > 9950X for llama.cpp, with the V-Cache providing measurable gains particularly at larger prompt sizes (1024–2048 tokens).
CPU-Only LLM Inference Tokens/secReal-World Data
| Model | Quant | 9950X Tok/s | 9950X3D Tok/s | Notes |
|---|---|---|---|---|
| Mistral-7B-Instruct | Q8_0 | ~108 pp | ~114 pp | Prompt processing 2048 tokens |
| DeepSeek-R1-Distill-Llama-8B | Q8_0 | ~9.0 tg | ~9.2 tg | Text generation (memory-bound) |
| DeepSeek-R1-Distill-Llama-8B | Q8_0 | ~108 pp | ~119 pp | Prompt processing 1024 tokens |
| granite-3.0-3b-a800m | Q8_0 | ~390 pp | ~465 pp | Massive +19% prompt boost from cache |
| Qwen3-30B-A3B (MoE) | Q4_K_M | ~17 tg | ~17 tg | Sparse MoE — bandwidth-bound on both |
| DeepSeek-R1 70B | Q8 | ~3 tg | ~3 tg | DDR5 bandwidth bottleneck dominates |
pp = prompt processing (tokens/sec), tg = text generation (tokens/sec). Sources: OpenBenchmarking.org, Reddit r/LocalLLaMA community benchmarks.
Key Insight: V-Cache Helps Prefill, Not Decode
For interactive chat applications (short prompts, long generation), the $76 premium for 9950X3D delivers minimal benefit — text generation is DDR5-bandwidth-bound and both CPUs perform nearly identically. For batch processing, document summarization, or RAG pipelines (long prompts, short completions), the 9950X3D's cache advantage translates directly to 10–20% faster throughput.
ASUS ProArt X870E-Creator WiFi — The Budget Dual-GPU Enabler

ASUS ProArt X870E-Creator WiFi — the best-value AM5 motherboard for dual-GPU AI/ML builds
For AI and machine learning in a homelab, the CPU is only half the equation. The motherboard's PCIe lane configuration determines whether you can run one GPU or two — and on the AM5 platform, most X870E boards dedicate all 16 CPU PCIe 5.0 lanes to a single slot. The ASUS ProArt X870E-Creator WiFi is one of the few consumer boards that supports true x8/x8 PCIe 5.0 bifurcation, splitting those 16 lanes evenly across two physical x16 slots — enabling dual-GPU setups at full PCIe 5.0 x8 (~32 GB/s each).
PCIe Lane Architecture — CPU-Direct Lanes28 Lanes Total
| Slot | Electrical | Source | Notes |
|---|---|---|---|
| PCIEX16(G5)_1 | x16 / x8 / x8 | CPU (PCIe 5.0) | Primary slot. x16 alone; x8 when dual GPU or M.2_2 used |
| PCIEX16(G5)_2 | x8 / x4 | CPU (PCIe 5.0) | Shares bandwidth with M.2_2 |
| M.2_1 | PCIe 5.0 x4 | CPU | Dedicated — no sharing. Safe to always use |
| M.2_2 | PCIe 5.0 x4 | CPU | SHARES with GPU slot 2 — leave empty for x8/x8 |
| PCIEX16(G4)_3 | PCIe 4.0 x4 | X870E Chipset | Physical x16 slot, x4 electrical. Good for 3rd GPU |
| M.2_3, M.2_4 | PCIe 4.0 x4 | X870E Chipset | No lane sharing |
PCIe Bandwidth Configuration — Visual Guide
Best for: single flagship GPU (RTX 5090, RTX 4090)
Best for: dual GPU AI/ML (48 GB+ VRAM total)
Is x8 Enough for AI?
Yes — for inference, x8 is massive overkill. LLM inference keeps the entire model in VRAM; only token data (bytes, not gigabytes) crosses PCIe per step. Even training with data parallelism only synchronizes gradients, and PCIe 5.0 x8 at 32 GB/s handles dual RTX 5090 gradient sync with room to spare. The only workloads that saturate x16 are GPU Direct RDMA multi-node training clusters — not relevant for homelab.
X870E Motherboard Showdown — Which Boards Support x8/x8?
| Motherboard | x8/x8 Dual GPU | 10GbE | M.2 Gen5 | Price (May 2026) |
|---|---|---|---|---|
| ASUS ProArt X870E-Creator | Yes — full x8/x8 PCIe 5.0 | Yes (Marvell AQtion) | 2x (1 shared) | ~$480 |
| ASRock X870E Taichi | Yes — x8/x8 | Yes (5GbE only) | 1x Gen5 | ~$450–500 |
| MSI MEG X870E Godlike | Yes — x8/x8 | Yes (10GbE) | 2x Gen5 | ~$1,100+ |
| Gigabyte X870E AORUS Master | No — x16 only | No | 1x Gen5 | ~$500 |
| ASUS ROG Crosshair X870E Hero | No — x16 only | No | 2x Gen5 | ~$700 |
Only 3 X870E boards support true x8/x8 dual GPU. The ProArt is the only one with 10GbE at under $500 — making it the clear value winner for homelab AI builders.
Why the ProArt X870E-Creator Is the Best Budget AI/ML Motherboard
1. Dual x8/x8 PCIe 5.0 — The Killer FeatureRare on AM5
Only a handful of X870E boards split CPU PCIe lanes for dual GPU. The ProArt is the most affordable option with this capability. Dual RTX 5090s at x8/x8 have the same per-GPU bandwidth as PCIe 4.0 x16 — the previous generation's maximum. For AI inference, this is more than sufficient.
2. 10Gb Ethernet Onboard — No Add-In Card Needed
Built-in Marvell AQtion 10GbE saves a PCIe slot and $100+ on a separate NIC. Critical for fast model transfers from NAS, distributed inference setups, and loading large datasets from network storage.
3. Triple-GPU CapabilityCommunity Proven
Reddit r/LocalLLaMA users have demonstrated 3x GPU configs on this board: GPU 1 at PCIe 5.0 x8, GPU 2 at PCIe 5.0 x4 (with M.2_2 populated), and GPU 3 at PCIe 4.0 x4 via the chipset slot. For inference workloads — where VRAM capacity matters more than PCIe bandwidth — this enables up to 72 GB VRAM with 3x RTX 4090 or 96 GB with 3x RTX 5090.
4. 4x M.2 (2x Gen5) for Fast Model Storage
M.2_1 is dedicated PCIe 5.0 x4 (no sharing) — perfect for a boot/model NVMe drive. M.2_3 and M.2_4 provide additional PCIe 4.0 storage from the chipset with no lane conflicts. Loading a 70B-parameter model from Gen5 NVMe (~16 GB/s) takes under 5 seconds.
5. 5-Year Warranty & 16+2+2 VRM — Built for 24/7
80A power stages, ProArt Creator Hub monitoring, and a 5-year warranty (vs. industry-standard 3-year) make this board suitable for always-on homelab operation. Confirmed working for Proxmox dual GPU passthrough (VFIO).
Here is my ProArt X870E-Creator Budget AI/ML Build
Buying these parts using the links below will earn me a commission on Amazon. Prices may change, given the craziness in the market today, but my goal was to not invest in a Threadripper rig with the WRT Sage motherboards which would cost an arm and a leg.
3x NVIDIA RTX PRO 4000 Blackwell Graphics Card - 24GB GDDR7 ECC Memory, PCIe 5.0 x16, 4X DisplayPort 2.1b, Single Slot Full Height AI Workstation GPU, Retail Packaging

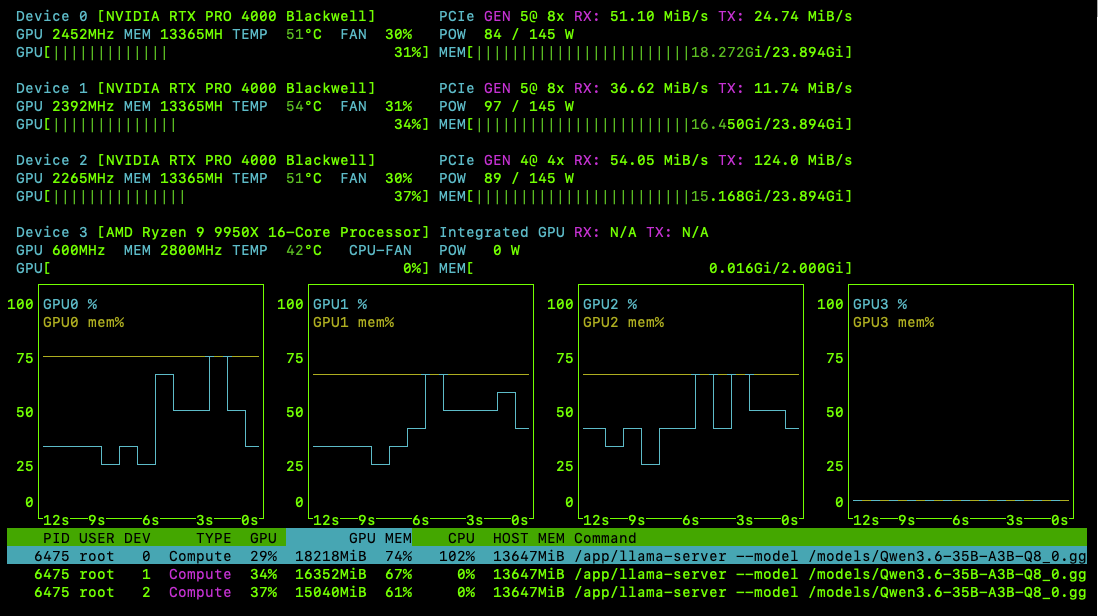
At a little under $2000, this is the best way to get three of these to get about 72GB of VRAM. Two of these will run on PCIe 5.0 at 8x, about 64GB/s and the third one will run on PCe 4.0 at 4x, about 32GB/s. As mentioned earlier, for inference workloads, this difference is negligible especially given the tensor parallelism AND if you are running MOE models like the Qwen3.6_35B_A3b which leaves more than enough room for the KV Cache. Honestly, you can run that model with just 2 cards, but 3 gives me about ~438 tokens/sec for short input and ~148 tokens/s for long input for Prompt eval. The output throughput averages about ~111 tokens/sec for all lengths from 64 to 512 tokens. At 10 parallel requests, I am able to process about 15.4 requests/sec which is pretty respectable for a local AI Rig. I was able to get about 148 tokens/s for long context input processing of 556 input tokens.
Buy It on AmazonBest of all!!! This is a single-slot GPU that runs at 140W. So I could get away with a 1000W Power Supply. And they come with adapters that convert the 12-pin to the 8-pin PCIe power connector which is great since I need three of these.
ASUS ROG Strix 1000W Platinum (Fully Modular Power Supply, 80 Plus Platinum Certified, ATX 3.1, Cybenetics Lambda A+, GaN MOSFET, GPU-First Intelligent Voltage Stabilizer, 10-Year Warranty)

At $217.00, this modular power supply is a no-brainer. GaN MOSFET delivers superior power efficiency by up to 30% and a more organized internal layout for cooler operation "GPU-First" voltage sensing with patented-intelligent voltage stabilizer enhances voltage delivery by up to 45% to your graphics card for smoother gameplay and unwavering performance Large ROG heatsinks cover critical components, delivering lower temperatures and noise than reference designs. Dual ball fan bearings can last up to twice as long as sleeve bearing designs 0dB technology lets you enjoy light gaming in relative silence. ATX 3.1 compatible with enhanced voltage and current regulation, and PCIe 5.0 Ready. I always go for platinum instead of gold or silver or bronze.
Buy It on AmazonCrucial Pro 64GB DDR5 RAM Kit (2x32GB), 5600MHz (or 5200MHz or 4800MHz) Desktop Memory UDIMM 288-pin, Compatible with 13th Gen Intel Core and AMD Ryzen 7000 - CP2K32G56C46U5

The price of RAM these days, is crazy. But I wanted to make sure I get 5600MHz memory and Crucial is a no-brainer. Micron is the best, especially for those who aren't looking for flashy RGB or overclocking. This memory says what it does. Works great with the AMD Ryzen 9 9950X or 9950X3D processors. You can only populate 2 of these sticks, otherwise, they downclock due to the limitations of this board, but our goal is VRAM and not DRAM. This is non-ECC memory and while I run Ubuntu Server 26.04 LTS, anything less than 64GB on a server(-like) build is underwhelming. Also comes in handy if 72GB of VRAM isn't enough and you need to offload some to the CPU. Slower, but still an option for things like KV Cache instead of the OOM scenario.
Buy It on AmazonASUS ProArt X870E-CREATOR WiFi AMD AM5 X870E ATX Motherboard PCIe® 5.0 x16 Slots with Full Support for Next-gen GPUs, 16+2+2 Power Stages, DDR5, Dual USB4®, 10 Gb & 2.5 Gb LAN, WiFi 7, Four M.2 Slots

The best AM5 motherboard in the market today, period. 10Gbe ethernet. DO NOT Populate that second M.2 Slot. That will rob your second GPU and switch it to PCIe 5.0 @4x which you do not want. You can still add more m.2 sticks to the bottom two slots if you need extra storage. In my case, I installed a Samsung 990 Pro 4TB in the main m.2 slot which is convenient to open and that's all I need for an AI Inference box. This box also comes with Two USB-4 Ports for 40GBps thunderbolt 3/4 devices if you decide to go that route. This is my AI Server. I don't use WiFi. Keeping it to what you need gives you the most bang for the buck. Make sure you install the latest BIOS update (/cfr/4e71df4bb72d443c95449e2b/articles/8/b095ca0b5fe2b81bdda20ee96d6029fb.zip) using the convenient USB Flashback method. This is the latest stable BIOS update available as of date that I used. I've included it here for your convenience. Rename it to A5560.CAP and install it onto an empty FAT32 drive and you are all set. Go to ASUS and download it if you wish. I take no responsibility for your convenience.
Buy It on AmazonAMD Ryzen™ 9 9950X 16-Core, 32-Thread Unlocked Desktop Processor (OR) AMD Ryzen 9 9950X3D 16-Core Processor


Well, this is an AI Rig. I am not a gamer. I went with the 9950X (~$499.99), but also have the 9950X3D (~$639.99) on my main development server because I thought that it would be better because of the MariaDB and NodeJS workloads. For AI Inference, the 9950X is plenty. 16 Cores and 32 processing threads, based on AMD "Zen 5" architecture. 5.7 GHz Max Boost, unlocked for overclocking, 80 MB cache, DDR5-5600 support. For the state-of-the-art Socket AM5 platform, can support PCIe 5.0 on our motherboard. Supports 24 PCIe Lanes in total. Needed for us to achieve our GPUs to achieve PCIe 5.0 @ 8x x2 + PCIe 4x x1 bandwidth across our three cards. This is the best in class, whether you go with the one on the left or the one on the right.
Buy 9950X on Amazon Buy 9950X3D on AmazonNoctua NH-D15 G2 chromax.Black Premium Dual Tower CPU Cooler for AMD AM5/AM4 and Intel LGA1851/LGA1700/LGA1200 (Black) - and - AM5 CPU Contact Frame V2, Anti-Bending Secure Frame, All-Aluminum CNC, Even Pressure, for AMD AM5 Socket, Includes L-Shaped Screwdriver

 Hint, Hint: Use the screw driver that comes with the Noctua cooler. It's awesome.
Hint, Hint: Use the screw driver that comes with the Noctua cooler. It's awesome.
Processors these days do not come with a cooler. Liquid coolers fail in a few years and you find out the hard way. The CPU Frame, though totally unnecessary, gives a solid mount for your CPU, instead of the weird clip. I always go with noctua and a CPU Frame. So these are my recommendations. Back in the day, I had contact issues with an Intel i9-14900KS and a CPU frame would have saved me a lot of heartburn, and these days, always go with this setup. The Noctua mounting process is a little daunting, but follow the instructions and you will be fine. RTFM, like they say. It even comes with a nice magnetic driver that you can add to your collection and an adhesive noctua decal, which I thought was nice. The CPU Contact frame is just a simple aluminum rig that replaces your motherboard's built in CPU holder. Just open the screws, (they won't fall out the back) and stick the frame in. REMEMBER to use thermal paste PLEASE. I would install the CPU and the contact frame immediately once I remove the motherboard from the box. The motherboard has fragile and sensitive pins, and once bent, you will destroy the setup, so be extra careful, just align the processor right and place it in its spot. Watch a youtube video or something and be very careful.
Buy Noctua NH-D15 G2 on Amazon Buy AM5 CPU Contact Frame V2 on AmazonCooler Master QUBE 540 ATX Mid-Tower PC Case – Highly Customizable Modular Computer Chassis with Movable I/O Panel, Multi-Position PSU Mount, Tempered Glass Panel & Portable Handles – Moonstone - and - ARCTIC P12 PWM PST (5 Pack) - PC Fans, 120mm Case Fan, PWM Sharing Technology (PST), Pressure-optimised, Quiet Motor, Computer, 200–1800 RPM (0 RPM <5%) - Black


And now for the case ($69.99) and Fans ($42.99). I could have bought Noctua fans, but this is a budget build, and ARCTIC makes good static pressure fans at non-German prices. The case is perfect. All-steel, all holes. Remove every anti-dust filter from the case, please. We are building an air-cooled rig, and maximum airflow is essential to our workloads, especially in home environments. Now if you have cats walking over your machines like I do, then the annual (or every six months) maintenance is essential to eliminate all the hair and dust, but I've had no problems doing this for a few years now. The case is really different. The Power supply mounts in the front, leaving some room for the front panel that comes with the case. But for deadbeat boxes that are going to spend the rest of their life headless, I think it is amazing.
Buy Cooler Master QUBE 540 on Amazon Buy ARCTIC P12 PWM PST (5 Pack) on Amazon
I have two of these beauties so far. Last, but not least, use a good thermal paste. If you build a lot of machines, just get the 11 Gram or 37 Gram package. They come with the special nozzle that makes applying the paste to the CPU easy. I always use Thermal Grizzly Kryonaut. It is simply the best. Doesn't cake up after a year or two, just works. Worth the value of buying it in bulk if (A) you will use it multiple times, and (B) you know where to find it when you need it. I'm great at losing this stuff. In closing, here are some pictures of my setup which you might appreciate. Feel free to reach out if you have any questions / comments or need some help on your local AI Journey while I wait for these prices to come back to normalcy.

I realize that I could have much better results with an AMD ThreadRipper build, but the motherboard and GPU alone would blow the budget to over $2500, let alone more than 2 sticks of RAM. This budget build is based on my own best-of-consumer-grade needs, uses an AMD Ryzen 9 9950X or 9950X3D, the best x870e motherboad, letting me focus on what matters - Getting the latest greatest nVidia Blackwell professional GPUs that have a decent power budget of 140W each. I think that this build will be stable and probably take me through the next couple years as more and more open-weight models become accessible within the 72GB VRAM limit. Of course, I could upgrade the same machines to 2x RTX 5000 or 1x RTX 6000 Blackwell GPUs, but you get what you pay for.